abyssal v0.0.1 | 一个 AI 驱动的闭环科研工作台
写在前面的话
本来打算写长一点,从设计哲学铺到各条管线的技术架构,并开发的更加完善一点再发出来。但做到一半懒得继续了,写这类业务端应用实在没什么意思,还是回去写游戏引擎。大概过几个月需要水论文的时候会再捡起来。
另外这个项目是随手花了半个多月 AI coding 做的,基本功能应该完善了,bug 还有不少没修。说实话我并不精通 TypeScript,整个过程纯 vibe coding——不像写 C++ 我还会逐个功能去测试调试。斟酌阅读使用即可。
项目说明
不知道你是否有过这种经历——Zotero 管文献但不理解论文内容,Elicit 能做 AI 分析但维度不可定制,Obsidian 的知识连接全靠手动,写作时开个 Claude 窗口问来问去但引用全靠幻觉。四件事在实际研究中根本不是独立的,你在写某段论证的时候同时在调用文献分析、书目管理、知识管理和写作表达,但现有工具逼你在不同应用之间反复切换,每次切换打断一次心流。而这些软件背着历史包袱,想接入 AI 也很困难。
大多数 AI 辅助科研还停留在开个 Gemini、Claude、ChatGPT 你问我答的阶段。自媒体视频里描绘的“全自动科研”又过于遥远。两者之间有一片空白。
Abyssal 试图填这片空白。它在做 Zotero(文献管理)+ Elicit(AI 论文分析)+ Connected Papers(论文发现)+ Jenni AI(AI 学术写作辅助)+ Obsidian(笔记)五合一,以 AI + 概念锚定 串起整条科研链路。
这个项目的出发点是 AI 不取代人的判断,只是在整条链路里引入 AI 来提升效率、降低心智负担——另一种意义上可以理解为学术版的 Cursor。
概念锚定同理:概念不是标签,而是贯穿始终的组织基元,它有双语定义、成熟度等级、层级关系、搜索关键词、演化历史。概念框架的变更会自动触发影响分析,告诉你哪些映射和综述需要更新。从 Search 到 Article,概念是唯一不变的线索。
项目整体由文献库、阅读器、分析、图谱、写作和笔记六个页面构成。
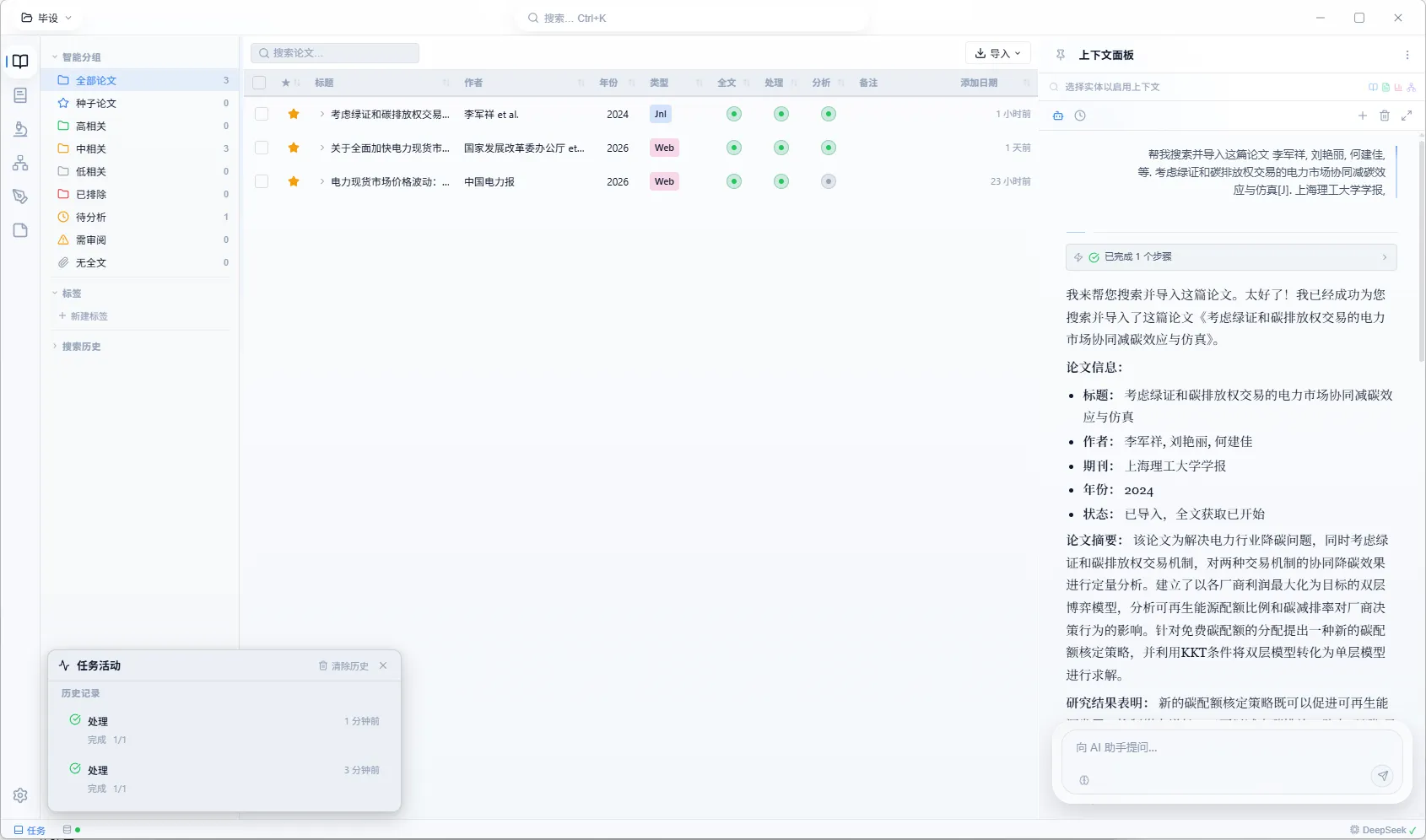
文献库
这部分着重介绍三个核心功能:论文的获取、处理、分析。
论文获取
解决的痛点很简单:拿到一个 DOI 或标题,不应该自己去各种网站手动找 PDF。
获取引擎分四层级联。Layer 0 是快速路径——对 arXiv、bioRxiv、PLOS、MDPI、Frontiers 等十种开放获取出版商,直接由 DOI 前缀构造 PDF 链接,零网络请求。DOI 以 10.48550 开头即知是 arXiv,直接拼 URL 下载。Layer 1 是并行侦察——对非 OA 论文,同时向 DOI 重定向、OpenAlex、CrossRef 三个源发起查询(Promise.allSettled,任一失败不阻塞),获取 OA 状态、可用 PDF 链接、出版商域名,结果带 TTL 缓存。Layer 2 是策略评分——将所有候选下载源按可靠性打分排序(Fast Path OA: 95 → OpenAlex PDF: 90 → CrossRef: 85 → 机构代理: 65 → PMC: 40 → Sci-Hub: 30),并根据失败记忆动态调整——某个出版商的 DOI 前缀在该源上反复失败,自动降权。Layer 3 是投机执行——高分候选源通过 Promise.any() 并行下载(默认 5 路并发),第一个成功的结果立即采用,其余取消;低分复杂源(PMC、知网、万方、Sci-Hub)按序兜底。
如果论文只有标题没有 DOI,会通过 CrossRef + Semantic Scholar 模糊匹配尝试恢复标识符。下载后可选通过 LLM 验证 PDF 内容是否与预期论文匹配(标题、作者对不对得上),防止下错论文。
导入方式支持手动上传 PDF、URL 导入(网页自动转 Markdown)、标识符搜索(DOI / arXiv / PMCID)、BibTeX / RIS 批量导入。
处理
处理管线的核心是把一份 PDF 变成可被 RAG 检索的结构化块。
版面分析使用 DocLayout-YOLO 模型,检测十种区块类型:正文段落、章节标题、图片及标题、表格及标题和脚注、公式及标题、废弃区块(页眉页脚之类)。PDF 的逐字符坐标数据与 DLA 检测框做空间匹配——每个字符归属到包含它的最小区块,生成结构化文本。阅读顺序通过文本区块中心点的 x 坐标聚类自动识别单栏还是双栏,双栏按”左栏从上到下 → 右栏从上到下”排序,跨栏元素优先排列。对扫描页面(字符密度 < 10 chars/sq_inch 自动触发),使用 Tesseract.js 多线程 OCR(4 worker 并行),支持中英文。
分块以章节为一级边界,章节内以空行分段,累积到 token 上限(默认 1024)时切出一个 chunk。相邻 chunk 保留 128 tokens 重叠避免语义截断,每个 chunk 记录前后段首句作为局部语境,通过字符偏移量二分查找精确记录起止页码和位置比例——检索结果可以直接跳转到 PDF 原文。
嵌入支持 OpenAI / Jina / SiliconFlow 等多种模型,向量存储在 SQLite + sqlite-vec 中,L2 距离 KNN 检索。
RAG 管线走四路召回:向量语义检索、BM25 全文检索(FTS5,支持 CJK 2-4 字符窗口)、基于概念映射关系的结构化查询、备忘录和标注的强制包含。检索时自动将概念定义和关键词注入查询变体,成熟概念获得更大的扩展因子(established 2.0×, working 1.5×, tentative 1.0×)。检索完成后有一道纠正式 RAG——LLM 从覆盖度、相关性、充分性三个维度评估结果质量,不足时自动执行修复策略(查询改写、分数阈值提升、top-K 扩大),最多重试两轮。上下文组装按论文分组、合并相邻 chunk、保证多样性(每篇论文至少一个最佳 chunk 入选),防止高分论文垄断上下文窗口。可选接入 Cohere / Jina / SiliconFlow 的重排序模型,未配置时退化为纯向量分数排序。
论文分析
分析采用双阶段架构。第一阶段是 Analysis Base——提取每篇论文的核心主张、方法标签(empirical / simulation / RCT 等)、关键术语。这一层与概念框架完全无关,是可复用的事实基础层,概念变更时不需要重跑。第二阶段是 Concept Mapping——将论文与框架中每个概念进行关系判定,生成映射矩阵。每条映射包含关系类型(支持 / 挑战 / 扩展 / 操作化)、置信度(0-1)、双语证据(AI 翻译的英文 + 原文引用,附 chunk 定位和页码)、审阅状态(AI 生成 → 用户接受 / 修正 / 拒绝)。
分析时不是把所有概念都扔给 LLM。三个维度筛选最相关的概念子集——用户标注信号(概念出现在高亮或笔记中)、引文邻域(被引论文已映射的概念)、语义相似度(嵌入向量邻近补充)。模型路由也会根据概念框架状态和论文相关性自动选择分析模式——零概念状态只做发现、低相关性论文跳过、中等相关性做元数据提取、高相关性使用前沿模型做完整映射。
用户可以在热力图或侧边栏中逐条审阅 AI 生成的映射——接受、拒绝、或修正(可调整置信度和关系类型)。审阅后的映射在后续 Synthesize 和 Article 阶段获得更高权重。双语证据卡片左栏原文、右栏 AI 英译,来源页码可点击跳转 PDF。
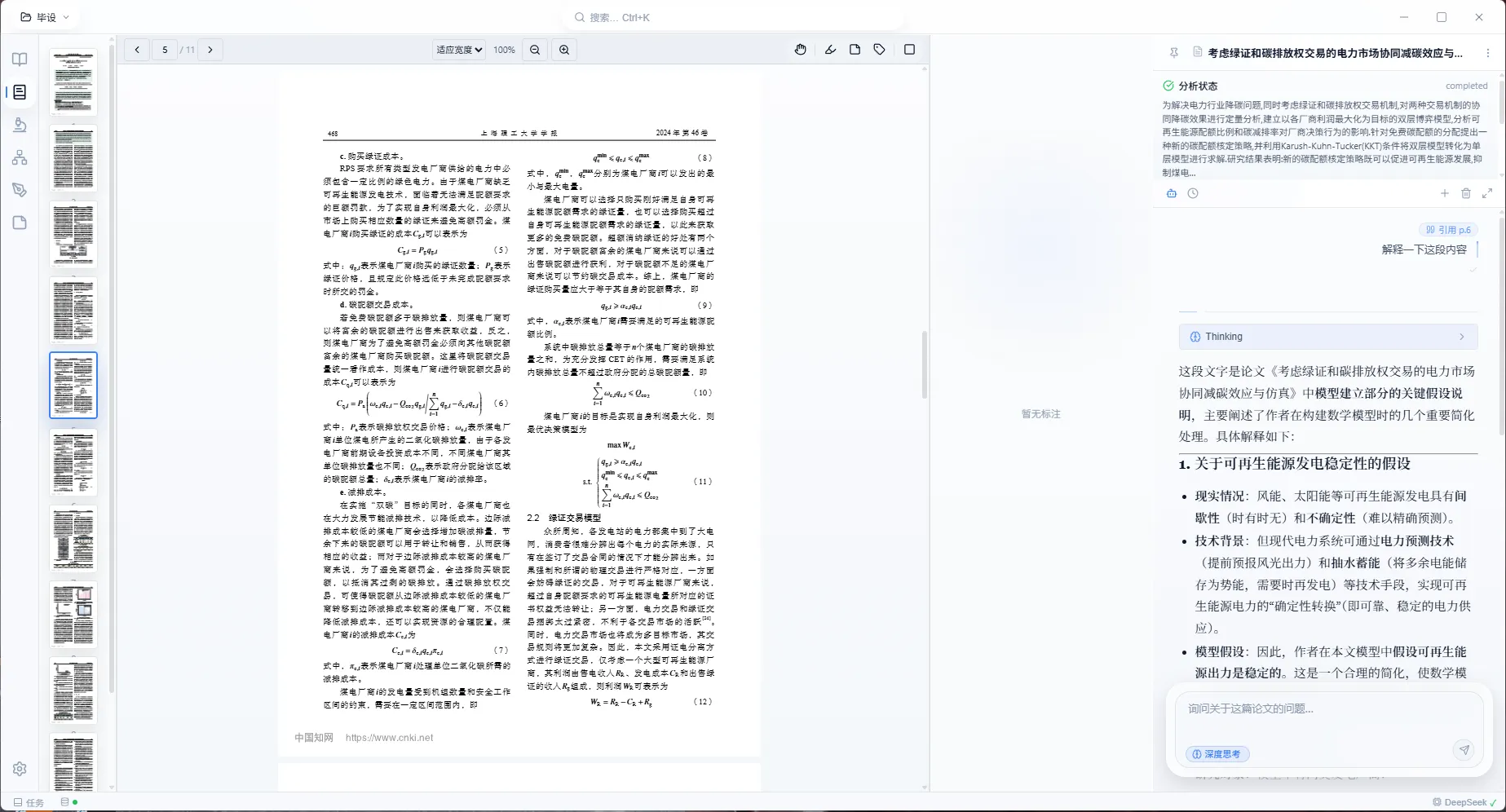
阅读器
做了两种阅读器,PDF 和网页。核心不是阅读器本身,而是与右侧 AI 的实时交互。
PDF 阅读器基于 pdf.js,四层渲染架构——文本层(选中和 OCR 坐标)、Canvas 层(PDF 渲染)、标注层(高亮 / 笔记 / 概念标签)、交互层(鼠标事件和区域选择)。支持缩放、缩略图导航、跨页选择,大 PDF 使用虚拟窗口和内存预算管理。网页阅读器对导入的网页内容(自动转 Markdown)提供相同的标注工具集。
标注系统支持选中文本后直接关联到概念框架中的某个概念,跨页选择自动生成 groupId 原子化创建,标注回写 PDF 保持离线阅读时仍可见。
AI 侧边栏是这部分的核心交互点。五个标签页:摘要(分析报告)、映射(双语证据 + 审阅按钮)、标注列表、备忘录、相关论文。AI 通过 RAG 获取当前论文和整个知识库的上下文来回答问题,证据卡片中的页码可直接点击跳转 PDF 对应位置。用户的高亮和笔记会自动注入后续分析的 LLM prompt 中——你在阅读时随手记下的想法,会在所有后续 AI 生成环节被看到。
分析与图谱
这部分 bug 可能有点多,还没做完。
知识图谱基于 Graphology(图数据结构)+ Sigma.js(WebGL GPU 加速渲染)。四种节点类型:论文、概念、备忘录、笔记。七种边类型覆盖引用关系(论文间的引用网络)、概念支持/冲突/扩展(论文与概念的映射关系)、语义邻近(基于嵌入相似度)、概念提及(笔记中提及的概念)、笔记关联(论文与笔记/备忘录的链接)。
交互上支持节点点击聚焦并在右侧面板显示详情、N 跳邻域聚焦(1 跳 / 2 跳 / 全局)、边类型按层切换显示隐藏、相似度阈值滑块过滤语义边、图搜索框加键盘导航。布局使用 ForceAtlas2 力导向算法在 Web Worker 后台计算,支持手动拖拽固定节点位置。
文献发现是一条八步管线。从用户标记为种子的论文出发(分公理级、里程碑级、探索级,不同级别获得不同的引文遍历深度),同时向后引用、向前引用、相关论文三个方向做广度优先遍历,每个种子最多扩展 200 篇。被两个以上不同种子引用的论文被标记为”桥接论文”,后续筛选中获得 1.5× 权重加成——这些往往是连接不同研究社区的关键文献。同时对框架中每个活跃概念,用名称和搜索关键词组合生成查询在 Semantic Scholar 等引擎中搜索。全局按 DOI → arXiv ID → 标准化标题三级 key 去重后,LLM 每 5 篇一批评估相关性(0-1),输出结构化评分和理由。最终有效分数 = 相关性分 × 桥接权重,按阈值分为高/中/低/排除四档,论文和引用边在同一事务中写入数据库。
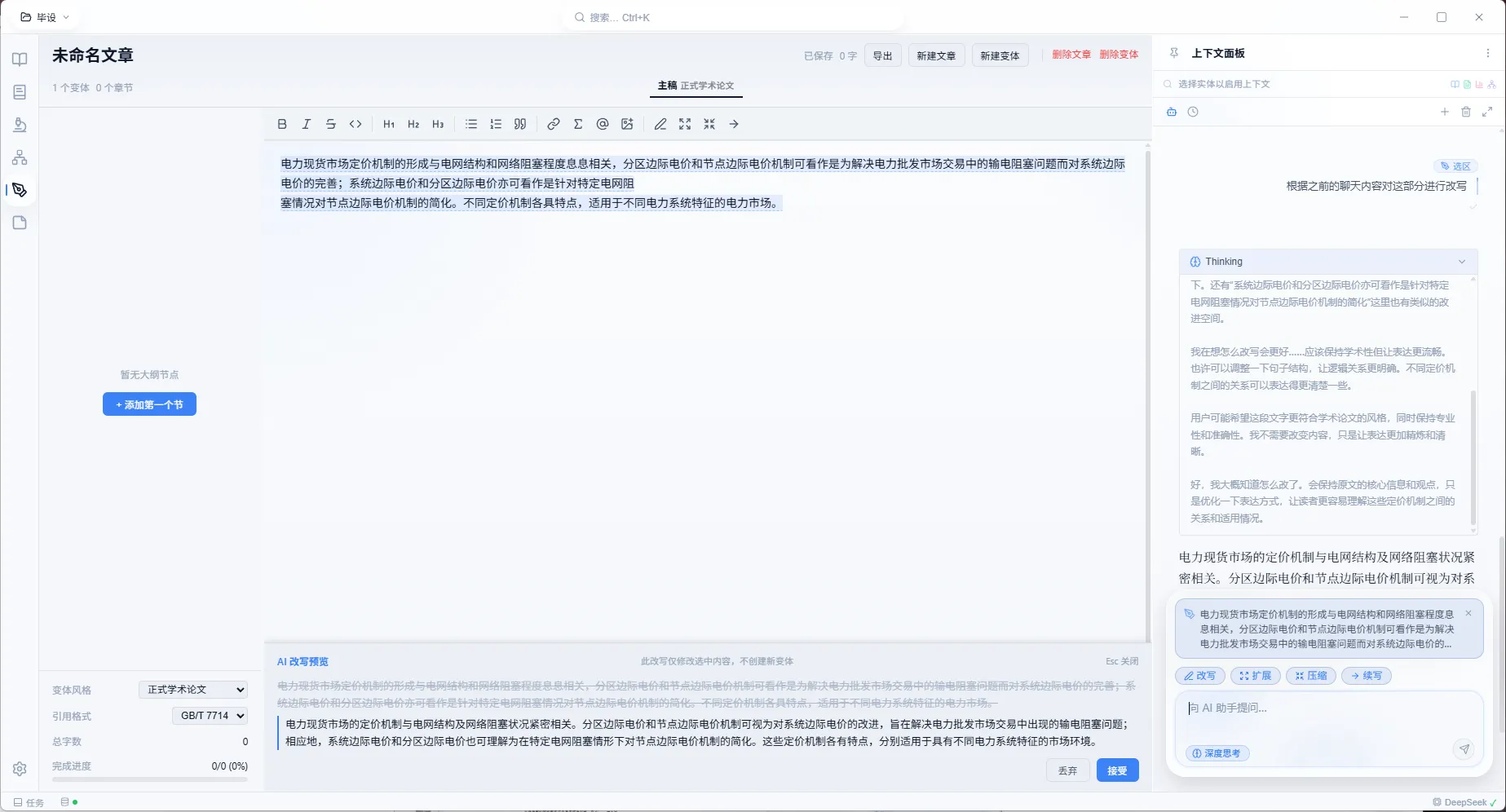
写作管线
编辑器基于 TipTap(ProseMirror),做了几个学术写作的深度定制:输入 [@ 触发论文自动补全,插入后带删除保护(需两次退格)防止误删;$...$ 行内公式和 $$...$$ 行间公式由 KaTeX 实时渲染,自动编号加交叉引用;脚注导出为 \footnote{};AI 流式块是运行时节点,显示 AI 实时生成的内容,完成后用户选择保留或丢弃,不会被序列化到文档。每个段落分配 UUID 记录人工编辑状态,用于段落保护。
段落保护是写作管线里比较重要的一个机制。用户手动修改过的段落被标记为”受保护”,AI 重新生成章节时系统提示中注入保护指令,生成完成后自动校验受保护段落是否被保留(编辑距离 < 2%),若 AI 遗漏或篡改了受保护段落,系统会强制恢复原文到近似位置。
导出系统支持 LaTeX(ProseMirror JSON → 完整 LaTeX 文档,带章节结构、引用命令、公式、表格、脚注、交叉引用)、BibTeX(自动生成 .bib 文件,标题双花括号保护大小写)、Markdown、DOCX。引用格式支持 APA / IEEE / GB/T 7714 / Chicago 四种样式,基于 CSL 引擎动态切换。
这部分也还没做完,最理想的情况下,用户拿到导出的 .tex + .bib 后只需要做两件事:选模板填元数据(作者、机构、摘要、关键词),以及编译后微调浮动体位置——后者是 LaTeX 本身的问题,Overleaf 用户也要做。正文、引用、公式、表格、章节结构这些占论文 90% 工作量的部分,可以做到导出即可用。这条管线的定位是高质量初稿生成器,不是 LaTeX 替代品——用户在 Abyssal 里完成思考、检索、组织、写作,最后十分钟在 Overleaf 里完成排版。
笔记
笔记分两层。备忘录是快速灵感捕获,简短片段,纯文本输入,可链接论文、概念、标注、大纲条目。笔记是结构化研究文档,长篇,使用完整的 TipTap 富文本编辑器,可链接论文和概念。两者都支持向量化嵌入后参与 RAG 检索。
两层之间有一条渐进式知识固化路径:备忘录可以升级为笔记(将零散灵感整理为结构化文档,自动建立双向链接),笔记可以升级为概念(将成熟的笔记提升为概念框架中的”试探性”概念,提取标题、定义、关键词)。这条路径模拟的是真实的研究认知过程——碎片灵感到结构化思考到正式理论框架。
备忘录和笔记在分析、综述、写作三个阶段都以绝对优先级注入 LLM 上下文。你在阅读时随手记下的想法,会在所有后续 AI 生成环节被看到。
使用方法
下载
基于 GitHub Release,目前只打包了 Windows 版本,下载安装即可。
https://github.com/xuanxuanQAQ/abyssal/releases/tag/v0.0.1
API 申请
由于本项目是个人兴趣,我也没有实力做商业化,所以 API 大家自己去申请吧。
本项目至少需要配置一个 LLM 和一个 Embedding。最低成本的组合是 DeepSeek(LLM)+ SiliconFlow(Embedding),两者都有免费额度或价格极低。LLM 和 Embedding 可分别选择不同供应商,只要各配一个即可。
必需(至少各配一个):
| 服务 | 用途 |
|---|---|
| DeepSeek | 默认 LLM(分析、综述、写作) |
| SiliconFlow | 默认 Embedding(语义搜索依赖向量化) |
可选 LLM(替代或补充):
| 服务 | 说明 |
|---|---|
| Anthropic Claude | 按 token 计费,分析和写作质量最好 |
| Google Gemini | 1M 超长上下文,有免费额度 |
| 豆包(ByteDance) | 256k 上下文,国内访问稳定 |
| Kimi(Moonshot) | 262k 上下文,长文本能力强 |
| SiliconFlow | 聚合平台,一个 key 覆盖 LLM + Embedding + Rerank |
可选 Embedding(替代 SiliconFlow):
| 服务 | 模型举例 |
|---|---|
| OpenAI | text-embedding-3-small |
| Jina AI | jina-embeddings-v3 |
可选 Rerank(提升搜索质量):
| 服务 | 说明 |
|---|---|
| SiliconFlow | bge-reranker-v2-m3 |
| Cohere | rerank-v3.5 |
| Jina AI | 多语言 reranker |
Rerank 不是必需的,没有配置时退化为纯向量分数排序,搜索仍可正常工作。
论文发现(全部免费):
| 服务 | 说明 |
|---|---|
| OpenAlex | 开放学术数据库 |
| Semantic Scholar | 不好用,不推荐 |
可选 Web 搜索:
| 服务 | 说明 |
|---|---|
| Tavily | 默认后端 |
| SerpAPI | Google 搜索代理 |
| Bing API | 微软搜索 |
| 博查(Bocha) | 国内替代方案 |
待办
以下为规划但还没实现的功能:
- 文献翻译
- 论文写作加入图片等素材支持
- 输出结构化引用
- 给项目做个 logo
- …
尾言
写到最后,终于明白了我对当下 AI 生态一直感到的那种割裂感来自哪里。套用之前在某自驾公司实习时学到的一个词——关键在于当下 AI 所推动的生产力是否是 Human-in-the-loop 的。不是的话,产出的东西大概率就是一坨。
不批判别人了。只是在我看来,AGI 尚未实现的当下,人在环仍然是所有工作不可或缺的部分。所谓 skill 代替员工、OpenClaw 自主开发年入百万之类的叙事,愈发觉得可笑。
本来还打算给这个项目做个视频,但懒,以后再说吧。
评论 Comments